О том что ссылки имеют значение при продвижении сайтов знает наверное каждый SEO’шник. Ходит немало споров о том, какие ссылки «работают», а какие «не работают», какие должны быть анкоры и какие темпы прироста ссылочной массы. Но как правило, всегда обсуждаются ссылки стоящие из html страниц и почему-то никто не рассматривает ссылки из документов в других форматах — doc и pdf, хотя поисковые системы отлично умеют их индексировать эти форматы.
Я провел небольшой эксперимент чтобы выяснить как поисковые системы относятся к ссылкам стоящим из pdf и doc файлов.

В начале апреля я создал тестовый сайт exp4.seo-experiments.ru, который не добавлял в аддурилки и на которые не ставил внешние ссылки из html страниц. После этого 10.04.13 я создал и залил на блог bakalov.info экспериментальный файл в формате doc в котором с уникального слова была проставлена ссылка на сайт exp4.seo-experiments.ru. Спустя некоторое время (03.05.2013) был создан экспериментальный файл в формате pdf, в нем также была проставлена ссылка на сайт exp4.seo-experiments.ru, но уже с другого уникального слова.
Эксперимент преследовал 2 цели:
-
Выяснить «переходят» ли поисковые системы по таким ссылкам или нет. Можно было конечно заморочиться и посмотреть логи, но на мой взгляд это лишнее, гораздо важнее попадет ли реципиент в индекс.
-
Выяснить передается ли по таким ссылкам «анкорный» вес, т. е. будет ли реципиент искаться по тексту ссылки.
Подведение итогов эксперимента несколько затянулось, но зато по прошествии 3 месяцев можно считать результаты окончательными.
Результаты в Яндексе
Оба файла были проиндексированы. Файл doc:

Файл pdf:

Однако сайт exp4.seo-experiments.ru в индекс Яндекса не попал:

Тем не менее была обнаружена одна интересная особенность — если при поиске по анкору из pdf файла, сам pdf файл находится:

То при поиске по анкору из doc файла, сам doc файл не ищется:

Если же взять уникальную фразу из doc документа и выполнить поиск в кавычках, то видно, что слово с которого стоит ссылка даже не отображается в сниппете, как будто его вовсе там нет:

Результаты в Google
Google порадовал значительно больше, чем Яндекс. Естественно оба файла были проиндексированы, сайт exp4.seo-experiments.ru попал в индекс и стал искаться по анкорам входящих ссылок. Из pdf файла:

Из doc файла:

Результаты в Поиске@Mail.ru
Оба документа попали в индекс, но по уникальному слову ищется только донор. Ссылка из pdf:

Ссылка из doc:

Итоги:
Ссылки из pdf и doc документов учитываются в Google, но не учитываются в других поисковых системах. Исходя из результатов эксперимента видно, что Google учитывает анкоры таких ссылок. Остается открытым вопрос — передается ли по таким ссылкам статический вес. Логика подсказывает, что стат вес должен передаваться, но для проверки этой гипотезы нужны дополнительные исследования.
Update от 13.08.2013. Сегодня в Google Webmaster Tools появились обе экспериментальные ссылки из doc и pdf файлов. Скриншот ниже, комментарии думаю излишни.
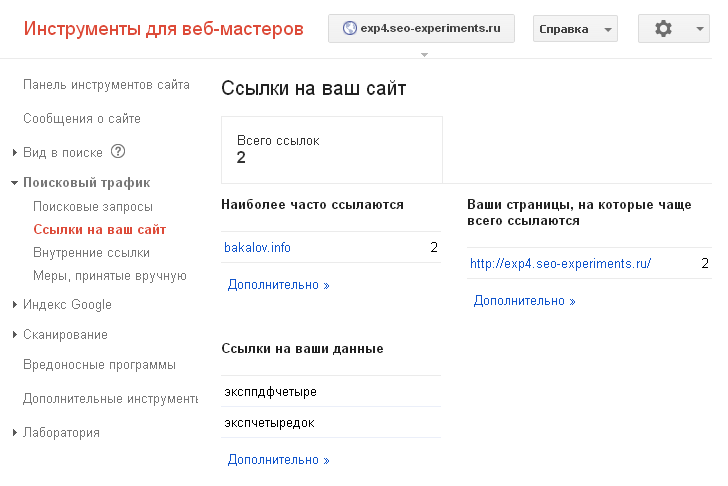






Эксперимент не закончен. Учлись ссылки в ЯВ и ГВ? Это самое главное.
А по поводу поиска по анкорам — что это показывает? Только индексацию текста анкора.
Devvver, спасибо за отличную идею. В YWT однозначно нет, т.к. сайт не в индексе. В GWT посмотрю вечером и обновлю пост.
Тоже пришёл к подобным выводам, хотя имел желание сделать более сложный эксперимент (каюсь не сделал в полном объёме), а именно: создать не менее 10 страниц в pdf-формате, только на 1-ю поставить ссылку, а остальные, по принципу матрёшки, раскрывающие тему, сделать ссылающимися последовательно с 1 по 10-ю.
Последняя статья должна была бороться за ТОП по среднечастотному ключу.
Есть основания предполагать, что в Гугле это дало бы результат, а Яша скорее всего прошёл мимо.
Во всяком случае в варианте из 2-х страниц, когда на первую есть входящая html-ссылка, а на 2-ю только из pdf, Google всё быстро индексирует и даже начинает ранжирование в поиске, а Яша только видит текстовку из 1-го pdf.
Учет подобной ссылки — это уже другое дело. Осталось только подождать результата от Яндекса.
В многих форумах можно прикреплять, а на некоторых сервисах и загружать свои pdf файлы.
Уже 4 месяца прошло, не думаю, что в Яндексе стоит ждать чуда
Спасибо огромное за эксперимент. Было интересно узнать о такой особенности индексации ссылок в документах.
Не так давно наткнулся на книгу SEO на экспорт, там говориться, что продвижение сайта в значительной мере поменяется в будущем. Как вы думаете ссылки умрут?